Третья часть из серии статей про реализацию больших чисел на C/C++, в начале по традиции ссылки на предыдущие части.
Наконец я добрался до реализации самых интересных операций. В совокупности с предыдущими наработками наши большие числа уже можно использовать для реализации различных алгоритмов, например, из области криптографии. О них я тоже скорее всего напишу, но уже чуть позже.
Умножение больших чисел
читать далее «Умножение больших чисел — реализация на C/C++» →
Приветствую всех, это вторая статья из серии про реализацию больших чисел на языке C/C++. В прошлый раз я рассказывал про общую структуру класса BigNumber и способ хранения большого числа в памяти. Были реализованы функции нормирования большого числа для печати и две арифметические операции: сложение и вычитание.
Не знаю точно, сколько еще статей будет на эту тему, но с этих пор в начале каждой буду оставлять ссылки для навигации.
В прошлый раз я обещал, что следующим шагом станет реализация деления и умножения больших чисел, но потом понял, что они не выполнимы без возможности сравнивать два числа. Кроме того, большинство алгоритмов отпадает без этого функционала. Поэтому в этот раз я приведу реализации всех операторов сравнения: ==, !=, >, >=, <, <=.
Важно! Дабы не растягивать и без того длинный листинг исходного кода, я не буду здесь публиковать сам класс BigNumber, его вместе с реализацией сложения, вычитания и нормализации вы можете найти в прошлой статье.
читать далее «Операторы сравнения больших чисел — реализация на C/C++» →
Совсем коротенькая шпаргалка про построение графиков на питоне, своего рода шаблон, который будет у меня в быстром доступе. Используется библиотека matplotlib, которая реализует все или почти все функции для построения графиков в стиле MatLab. Названия функций и аргументы очень похожи, но все же это Python, синтаксис тут гораздо приятнее, чем в матлабе.
Функция которую будем изображать
Для любого двумерного графика нужны точки, вектор значений X и вектор Y, значений прошедших через функцию. В зависимости от задачи это может быть сложнейшая математическая модель, либо, как в моем случае, простейшая функция.
|
|
def func(x): return [i**2 for i in x] |
Да, будем строить параболу! Для демонстрации вполне достаточно.
читать далее «Пример построения графика на Python с помощью библиотеки matplotlib» →
Доброго времени суток! У меня появилась небольшая проблема во время программирования контроллера в Zend Framework 2, моя среда разработки никак не хотела давать подсказок по любым объектам, связанным со встроенной ORM Doctrine.
Описание проблемы автодополнения
Я пользуюсь IDE под названием IntelliJ IDEA от прекрасной фирмы JetBrains с установленным плагином на PHP, который называется PhpStorm. Но поверьте мне, дело совсем не в ней, любая среда бы не смогла разресолвить методы встроенной в Zend Framework доктрины.
Но ближе к делу.
Idea любезно отвечает «No suggestions», мол «сори, не знаю такого», на просьбу показать методы объекта класса EntityManager, я даже сделал скриншот.
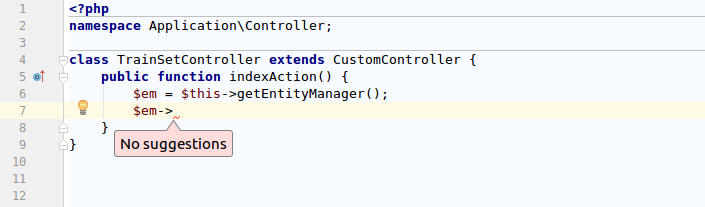
Танцы с бубном вокруг настроек «Include Path» не увенчались успехом, пришлось идти бороздить просторы англоязычного интернета. Решение нашлось не сразу.
читать далее «Подсказки в PhpStorm для Doctrine Entity Manager с Zend Framework» →
Доброго времени суток! Причиной возникновения этой заметки послужила ошибка, которую выкидывает phpMyAdmin при попытке импорта дампа базы из большого файла. Дословно она звучит примерно так: «Fatal error: Maximum execution time of 300 seconds exceeded in /opt/lampp/phpmyadmin/vendor/phpmyadmin/sql-parser/src/Lexer.php on line 227». Формулировка может отличаться в деталях. Из сообщения видно, что превышен максимальный временной лимит на исполнения скрипта, по этой причине дамп импортируется не весь и нам очень грустно. Но обо всем по порядку.
Не секрет, что для любого скрипта на PHP существуют стандартные настройки конфигурации, инициализированные в файле php.ini. Их там огромное количество и большинство из них трогать не рекомендуется.
Эти настройки глобальные, но каждый скрипт может лично для себя их изменять. Нас в первую очередь будет интересовать возможность увеличения, либо снятия лимита на максимальное время исполнения скрипта. Посмотрим как это сделать для любого скрипта и для phpMyAdmin в частности.
читать далее «Импорт больших файлов в phpMyAdmin» →

